Im Rahmen des HR-Battles auf persoblogger.de verteidigte Jan Kirchner vor kurzem die These, dass Algorithmen zukünftig menschliche Recruiter ersetzen können. Seine offenbar polarisierenden Statements zogen einige Aufmerksamkeit auf sich und ernteten nicht allzu viel Beifall. Es folgten einige Debatten. Geht das? Geht das nicht, dass Maschinen den (Vor-)Auswahlprozess übernehmen usw.?
Die skeptischen, teils gar ängstlich anmutenden Reaktionen sind womöglich auf fehlendes Wissen Bereich künstliche Intelligenz und maschinelles Lernen zurückzuführen. Ich möchte mit dieser Aussage niemandem zu nahe treten. Ich finde einfach, dass es uns allen helfen kann, etwas tiefer in das Thema einzutauchen – damit wir etwas besser verstehen, worüber wir da debattieren. (Das Thema wird uns noch eine Weile begleiten). Wenn wir wissen, wie Maschinen lernen, können wir besser einschätzen, wo die Möglichkeiten und wo die Grenzen liegen.
Wie gerufen kommt das wunderbare experimentelle Projekt R2D3, das uns “normalen Menschen” die Funktionsweise des Maschinellen Lernens auf eine einfache, visuelle Weise erklären möchte. Das Ergebnis gefällt mir so gut, dass ich es hier gerne ein wenig angepasst ins Deutsche übertragen möchte. Die wunderschöne Animation in englischer Sprache kann hier abgerufen werden.
* * *
“Maschinelles Lernen” beschreibt den Vorgang, bei dem Computer, unterstützt von statistischen Methoden und Modellen, die Erkennung von Mustern (Gesetzmäßigkeiten) “erlernen”. Das so erlangte künstliche Wissen, kann zur Generierung von Vorhersagen eingesetzt werden.
Im Folgenden wird am Beispiel eines Wohnraum-Datensatzes ein maschinelles Lernmodell aufgebaut, das selbständig entscheiden soll, ob sich ein Mietobjekt in New York oder in San Francisco befindet.
Übertragung in den HR-Kontext: Wir bringen der Maschine bei, auf Basis von alten Bewerbungen zu unterscheiden, welcher Bewerber passt und welcher nicht.
Schauen wir uns diese beiden “Stapel” an. Links haben wir die Höhenlage der Häuser in SF und rechts der Häuser in NY.
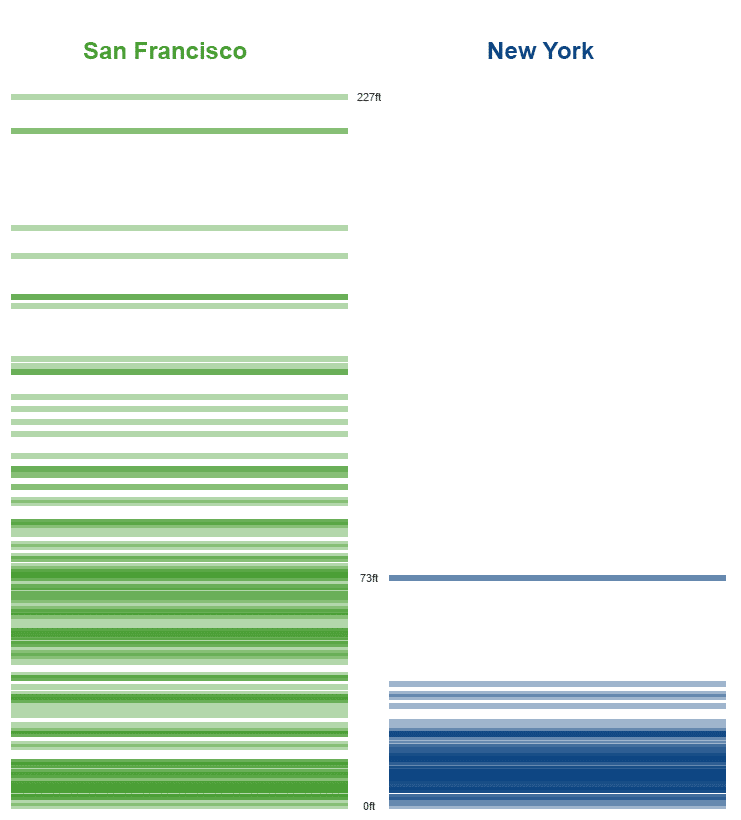
Müssten wir jetzt intuitiv eine eindeutige Regel für zukünftige Unterscheidungen anhand eines einzigen Kriteriums (Höhenlage) definieren, würden wir vermutlich festlegen, dass alles, was höher als 73 Fuß liegt, sich in SF befindet.
HR-Kontext: Stellt euch vor, dass es sich um zwei Bewerber-Stapel handelt. Links – passend, rechts – unpassend. Ersetzen wir mal gedanklich das Kriterium Höhenlage durch Berufserfahrung (Jahre). Alle die über z.B. 5 Jahren Berufserfahrung liegen, müssten mit Sicherheit passen.
Nun fügen wir ein weiteres Kriterium hinzu: den Preis pro Fläche. Es lässt sich eine weitere Gesetzmäßigkeit erkennen. Wohnraum ab einem Preis von $1776/sqft aufwärts liegt eindeutig nur in New York.
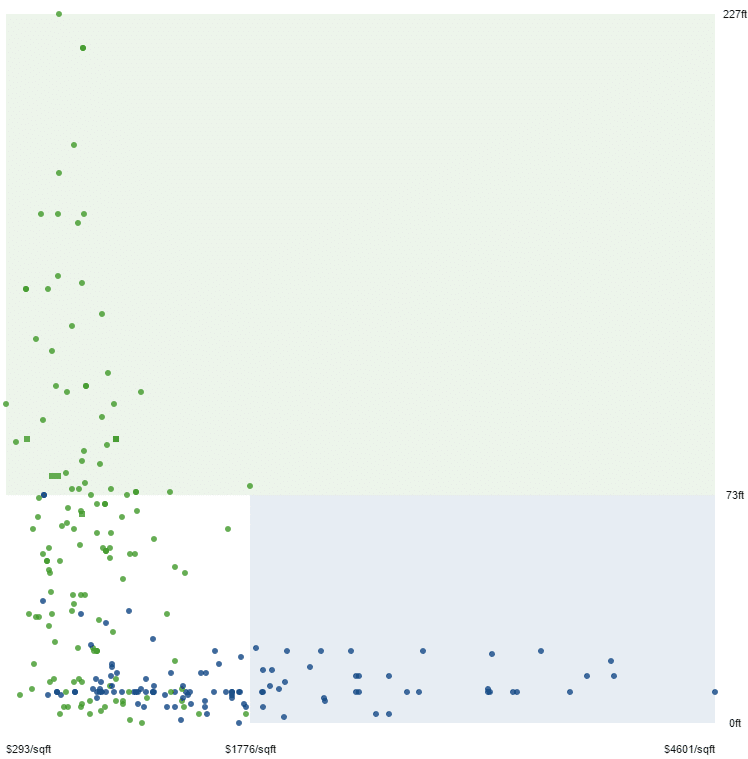
Ein gewisser Teil unserer Daten ließe sich also gemäß unseren bisherigen Erkenntnissen anhand der Höhenlage und des Preises der einen oder anderen Stadt zuordnen.
HR: Ersetzen wir gedanklich den Preis durch die Länge der Studiendauer. Es würde sich bei unserem hypothetischen Beispiel die folgende Gesetzmäßigkeit ergeben: Alle Bewerber, die mehr als 5 Jahren Berufserfahrung vorweisen, passen auf jeden Fall, und alle, die länger als 10 Jahre studiert haben, passen nicht.
So weit, so gut. Problematisch wird es bei der Unterscheidung des “gemischten” Teils des Datensatzes im weißen Rechteck – also Wohnraum in einer Höhenlage unter 73ft und in der Preiskategorie unter $1776/sqft, der sowohl in SF als auch in NY vorkommen kann.
HR: Bei unseren Bewerbern wäre es die Teil-Gruppe, in der die Bewerber mit unter 5 Jahren Erfahrung dennoch angenommen wurden und Bewerber mit unter 10 Jahren Studienzeit dennoch abgelehnt.
Wir benötigen offensichtlich weitere Kriterien. Insgesamt enthält der Wohnraum-Datensatz 7 Kriterien. Setzen wir sie alle jeweils ins Verhältnis zueinander, wie im oberen Chart, ergibt sich das folgende Bild, in dem eindeutig weitere Zusammenhänge vorherrschen, die jedoch mit bloßem Auge, Logik oder Intuition nicht mehr zu erkennen sind.
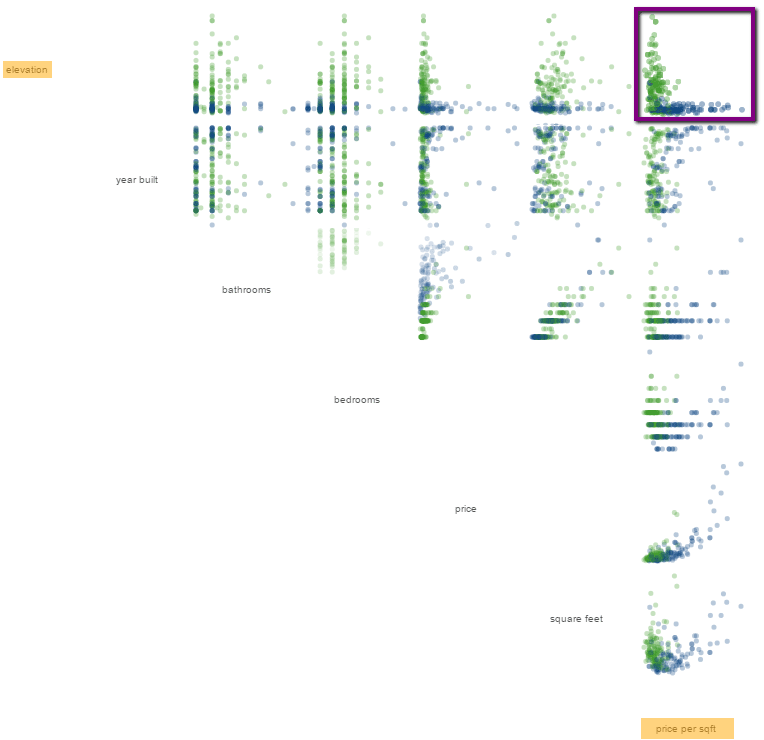
Spätestens jetzt kommt maschinelles Lernen zum Einsatz. Als Methode wird hier ein Entscheidungsbaum eingesetzt. Der Datensatz wird anhand eines Kriteriums nach dem anderen und anhand des dazugehörigen Entscheidungswertes (split point) immer wieder in zwei Gruppen gesplittet.
“Wenn die Höhenlage höher als X ist, dann ist das Haus vermutlich in SF, der Rest liegt in NY”. Dann geht’s weiter, “wenn der Preis über Y liegt, befindet sich das Haus in NY, der Rest liegt in SF”. Beim Lernprozess wird dabei bei jeder Spaltung ein optimaler Entscheidungswert gesucht, der den Datensatz möglichst sauber in zwei homogene Gruppen aufteilt.
HR: Stellt euch vor, dass wir unsere Kriterien Berufserfahrung und Studienzeit nun um SAP HR Kenntnisse (1-10), die englische Sprache (1-10) und die Abschlussnote (4-1) ergänzen. Dann nehmen wir uns jedes Kriterium vor, das wir jeweils anhand eines Entscheidungswerts in passend und unpassend aufteilen.
Denken wir nun an unsere erste intuitive Schätzung in der ersten Abbildung zurück. Wir haben angenommen, dass alle Objekte in einer Höhenlage ab 73Ft in SF liegen. Lässt man nun den gesamten Datensatz anhand des Kriteriums Höhenlage bei X=73Ft aufteilen, ergibt sich folgendes Bild.

Der Wohnraum, der höher als 73Ft liegt (als faktisch ab 74Ft), befindet sich zwar zu 100% in SF, aber wir vermissen eben eine ganze Menge Häuser, die fälschlicherweise in der NY Gruppe gelandet sind, obwohl sie doch in SF liegen.
HR: Vergleichbar wäre hier die Vorstellung, dass wir z. B. im Fall des Kriteriums Berufserfahrung zunächst intuitiv angenommen haben, dass 5 Jahre eine gute Grenze ist, um Passende von Unpassenden zu trennen. Bei der Aufteilung im Entscheidungsbaum fällt jedoch auf, dass wir so zu viele passende verlieren. Der Entscheidungswert muss wohl nachjustiert werden.
Mithilfe zusätzlicher mathematischer Methoden kann ein optimaler Entscheidungswert gesucht werden. Die Maschine lernt und findet für das Kriterium Höhenlage einen besseren Entscheidungswert (ab 28 Ft), der eine höhere Homogenität der Ergebnisse verspricht. Dennoch ist die Genauigkeit mit 82% noch zu schlecht.
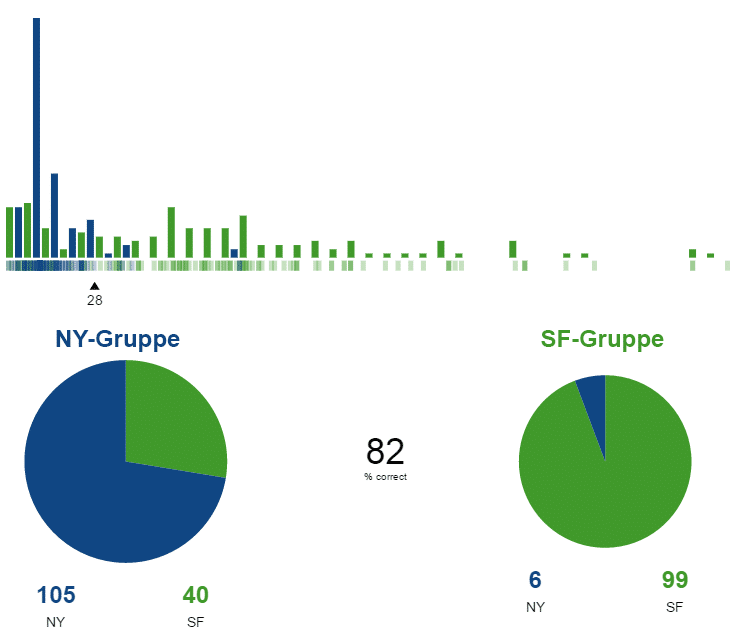
Führt man nun mehrere Aufteilungen unter Berücksichtigung der optimalen Entscheidungswerte nach einander durch, erhöht sich die Genauigkeit der Schätzung sukzessive. Wir teilen z.B. zunächst nach der Höhenlage, dann die beiden Ergebnis-Gruppen nach dem Preis, dann nach dem Baujahr usw.
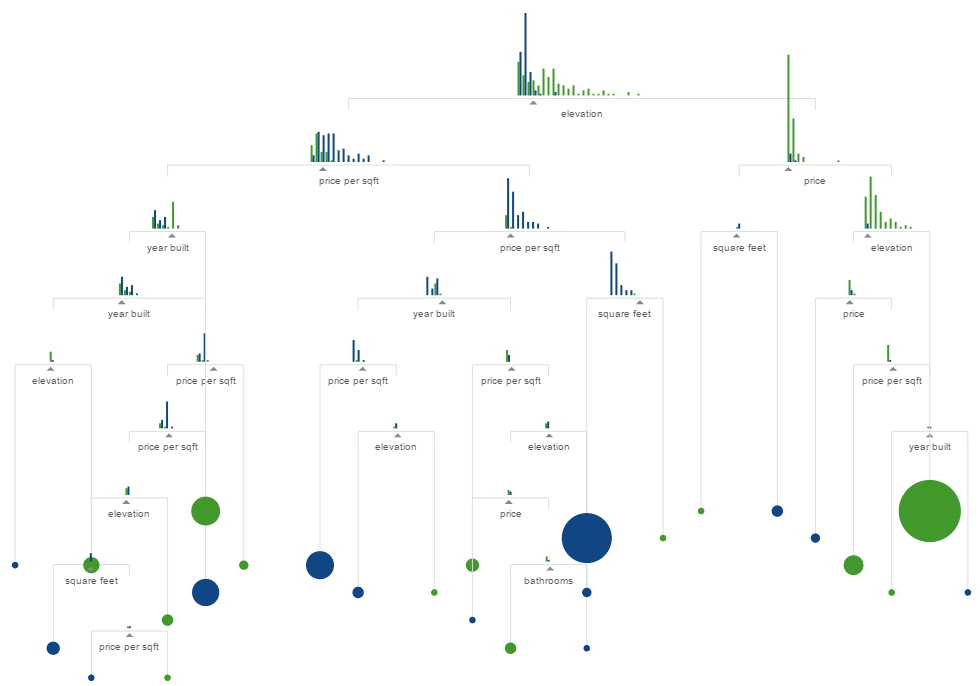
Die sauberen Gruppen werden aufgesammelt und zu SF oder NY zusammengefasst. Die Maschine hat gelernt, den vorhandenen Datensatz exakt aufzuteilen.
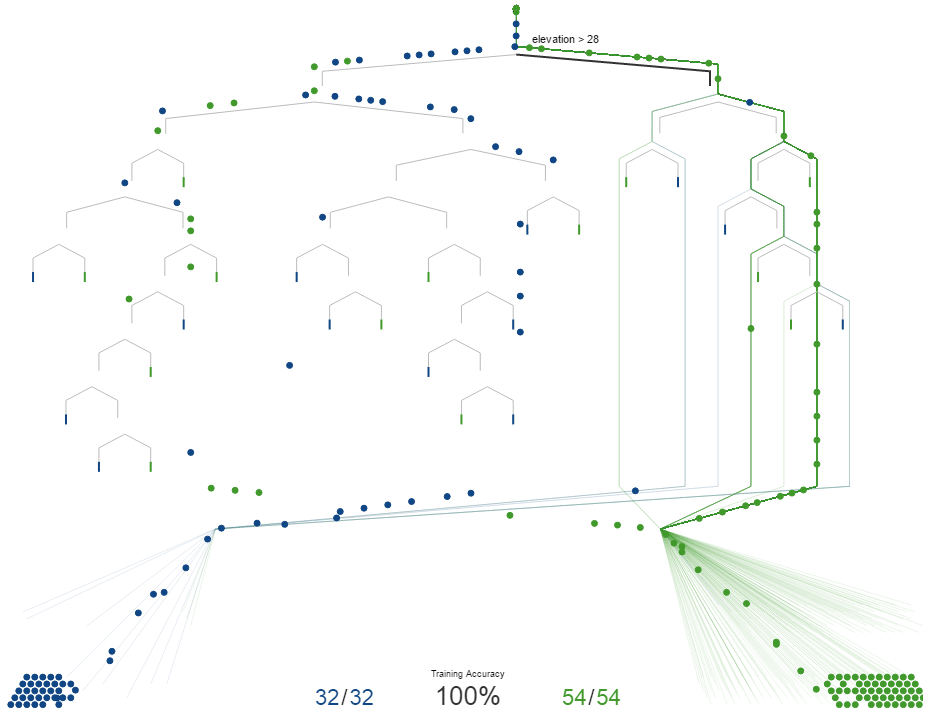
HR: Wer bis hier meine Übertragungen einordnen konnte, wird das Prinzip auf die passenden und die unpassenden Bewerber sicher übertragen können. Wir teilen zunächst z. B. nach Berufserfahrung bei dem optimierten Wert von 4 Jahren auf und erhalten nicht ganz aber fast homogene Gruppen. Die Gruppe der Unpassenden, die ein paar Passende enthält und die Gruppe der Passenden, die wiederum ein paar Unpassende enthält unterteilen wir jeweils wieder anhand von einem anderen Kriterium. Am Ende hat die Maschine die Bewerber sauber aufgeteilt.
Im nächsten Schritt muss das Model anhand von noch nicht bekannten Daten (neuer Datensatz) getestet werden, um zu prüfen, wie gut es für die Praxis geeignet ist. Bei größeren Abweichungen, kann an verschieden Stellen nachjustiert werden. Und so weiter und so fort. Ich denke, hier sollten wir erstmal Pause machen.
So kann maschinelles Lernen jedenfalls funktionieren. Ich hoffe, dass ihr diese Darstellung interessant fandet und meine HR-Übertragungen einigermaßen nachvollziehen konntet. So viel Zauberei ist hier wohl doch nicht dabei, oder? Werden die Maschinen nun alles übernehmen oder nicht?
Eins ist klar, ohne eine vernünftige Datenbasis läuft hier so oder so nix. Sammelt fleißig Daten, wenn ihr von Maschinen übernommen werden wollt 🙂 Oder zumindest, um zu belegen, dass ihr eben besser als die Maschinen seid.
(Liebe Mathematiker und Informatiker, sollten mir hier unverzeihliche sachliche Fehler unterlaufen sein, bitte ich um freundliche Hinweise.)