Personaler kennen ihre (Web-)Zahlen nicht. Es ist eine Verallgemeinerung. Aber sie stimmt. Wie viele Besucher kommen auf die Karriereseite, wie viele auf eine bestimmte Stellenanzeige, wo kommen sie her, wie viele Besucher kommen von einer bestimmten Jobbörse? Das sind Fragen, auf die, unserer Erfahrung nach, die Mehrheit der für die Rekrutierung neuer Mitarbeiter verantwortlichen Personaler keine Antwort haben.
Das ist schlecht. Denn die Kenntnis dieser Zahlen kann sehr hilfreich sein, wenn man z.B. begründete Entscheidungen bzgl. der Effektivität bestimmter Recruiting-Kanäle treffen möchte. Wir glauben, dass die Unkenntnis drei Ursachen haben kann: 1) Desinteresse 2) kein Zugang zu Web-Statistiken 3) keine Routine in der Auswertung. Gegen 1) und 2) können wir auf die Schnelle nichts tun. Aber bei 3) können wir schnelle Hilfe liefern.
Ich beschäftige mich in diesem Post mit Google Analytics. Dieses kostenlose Tool zur Erfassung von Web-Statistiken ist aufgrund des Funktionsumfangs und der Einfachheit der Implementierung eine zweckmäßige Empfehlung für Unternehmen, die recht oft in Anspruch genommen wird. Ich gehe also davon aus, dass Google Analytics auf Eurer Seite bereits installiert ist. Ihr seid nicht sicher?! Dann testet es doch zunächst HIER. Installiert? Jetzt müsst Ihr Euch „nur“ noch den Zugang vom Webmaster oder der IT besorgen. ;)
HR-ANALYTICS WHITEPAPER – MIT KPIs ZUM ERFOLG
JETZT KOSTENLOS HERUNTERLADEN
Nun zeige ich Euch, wie man die in der Einführung gestellten Fragen mit Google Analytics (GA) schnell beantwortet und zwar am Beispiel der Wollmilchsau HR-Jobbörse.
1. Wie viele Besucher kommen auf die Karriereseite?
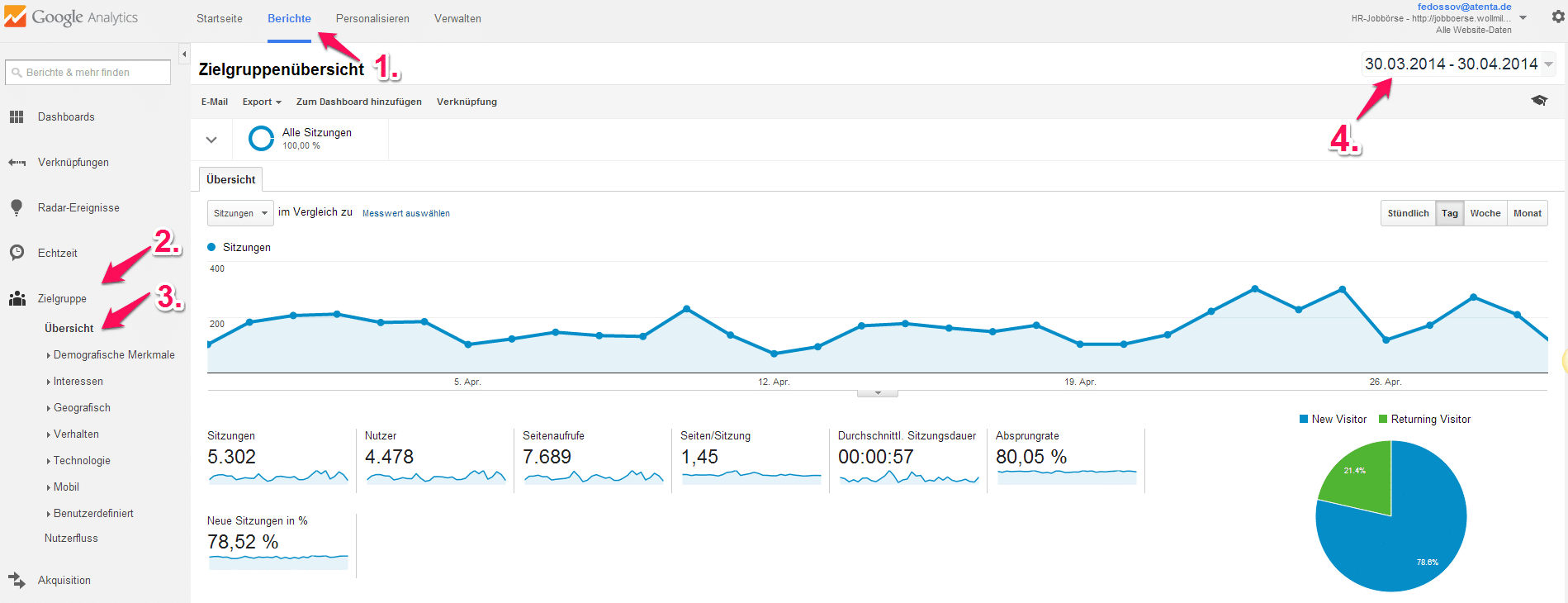
Wir wählen aus: Berichte -> Zielgruppe -> Übersicht -> Zeitraum und erhalten die Übersicht der Besucher für die gesamte Seite für den ausgewählten Zeitraum. Sitzungen beschreiben die Anzahl der Besuche auf der Seite. Besucht die gleiche Person, also Nutzer, Eure Seite zwei Mal, sind es zwei Sitzungen. Seiten pro Sitzung zeigen an, wie viele Seiten sich ein Besucher im Schnitt anschaut. Sitzungsdauer ist der durchschnittliche Verbleib eines Besuchers auf Eurer Seite. Absprungrate zeigt an, wie viele Besucher Eurer Seite nach der Betrachtung einer einzigen Seite wieder verschwinden. Neue Sitzungen zeigen an, wie hoch der Anteil der Besucher ist, die noch nie bei Euch waren. Also, unsere Beispiel-Seite wurde im laufenden Monat 5302 Mal besucht.
2. Wie viele Besucher landen auf einer bestimmten Stellenanzeige?
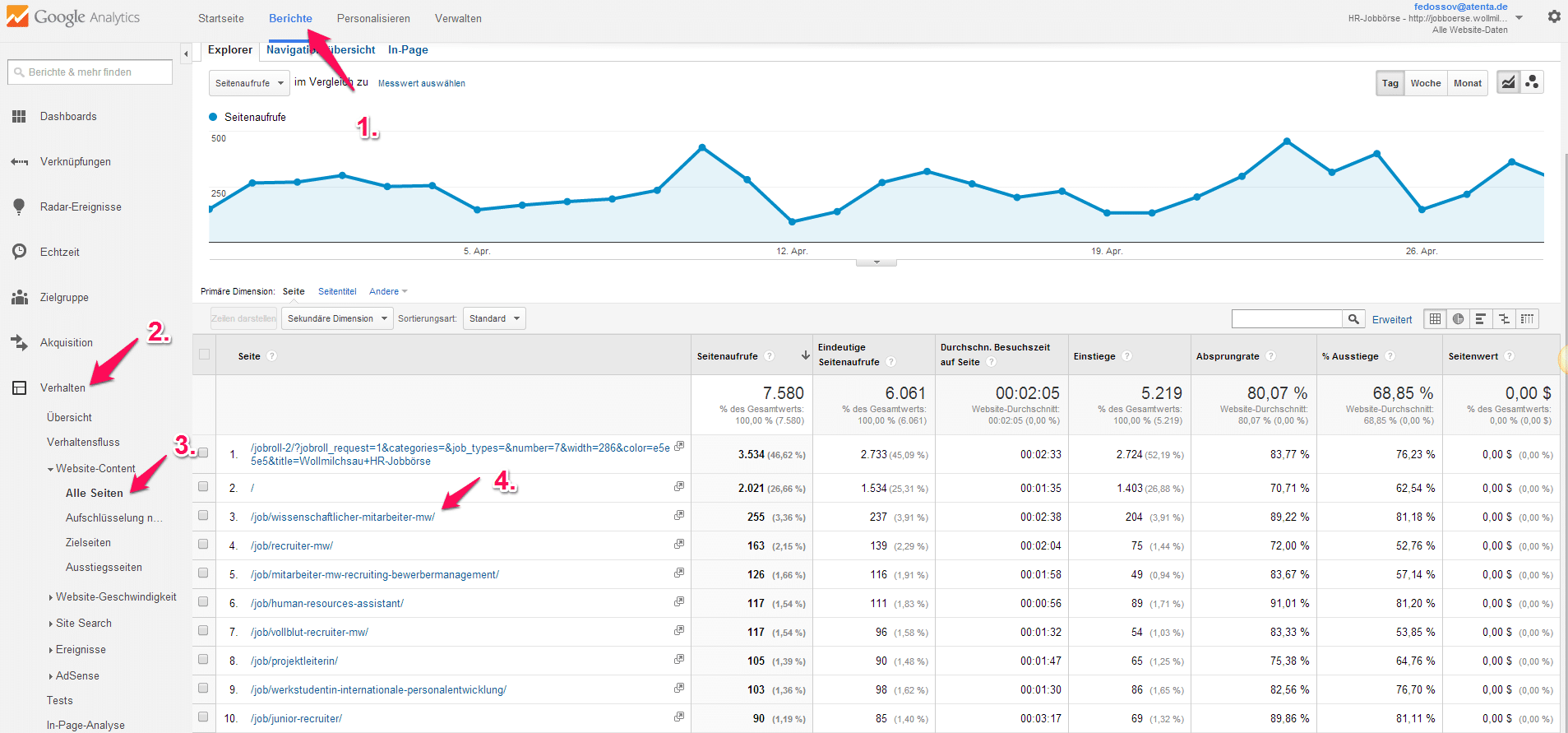
Wir klicken auf: Berichte -> Verhalten -> Alle Seiten -> und die Unterseite/Anzeige, die uns interessiert. Als Ergebnis erhalten wir den Besucher-Verlauf und weitere bereits bekannte Kennzahlen für die konkrete Anzeige.
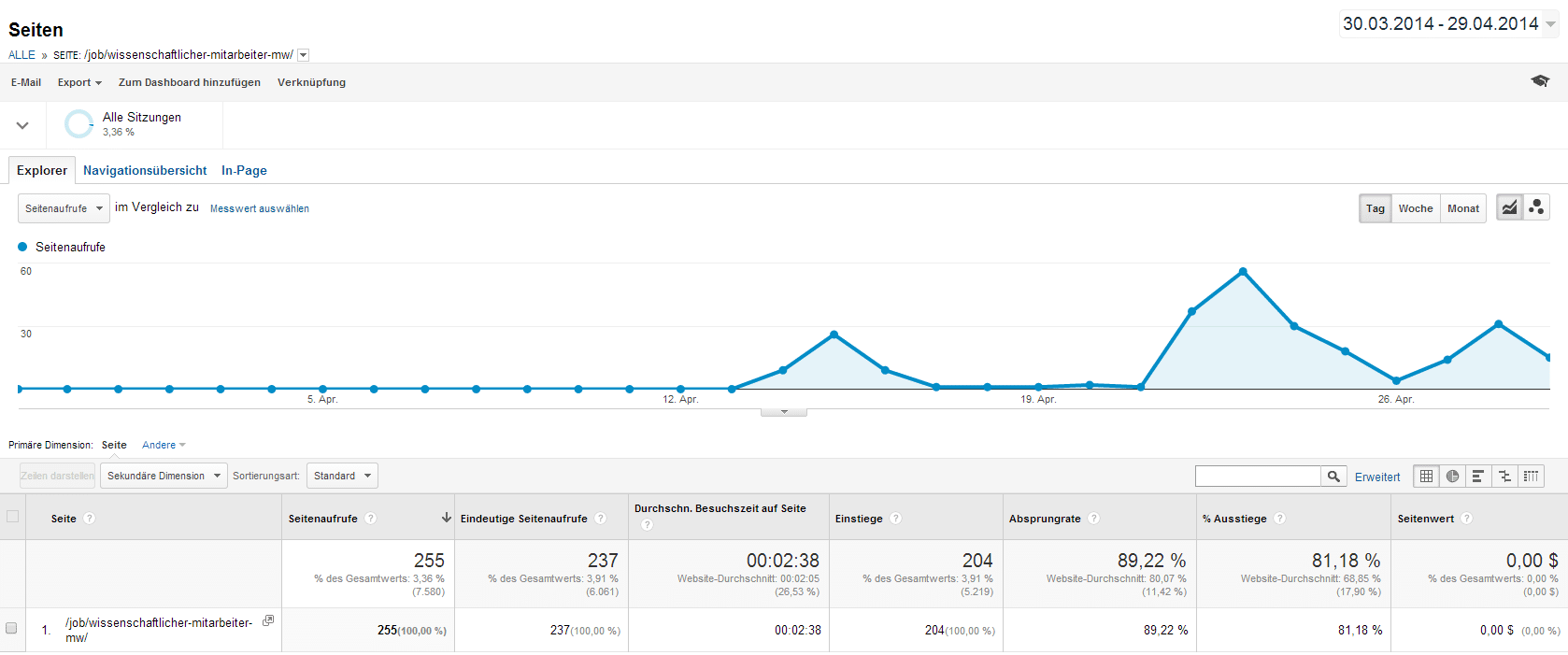
Nun, unsere Beispiel-Anzeige konnte offenbar vom 13.04-29.04. 255 Seitenaufrufe generieren. Die durchschnittliche Besucherzeit von 2:38 min. zeigt mir, dass die Anzeige offenbar von den meisten zumindest ausführlich gelesen wurde.
3. Woher genau kommen die Besucher, die Ihre Stellenanzeige/Seite angesehen haben?
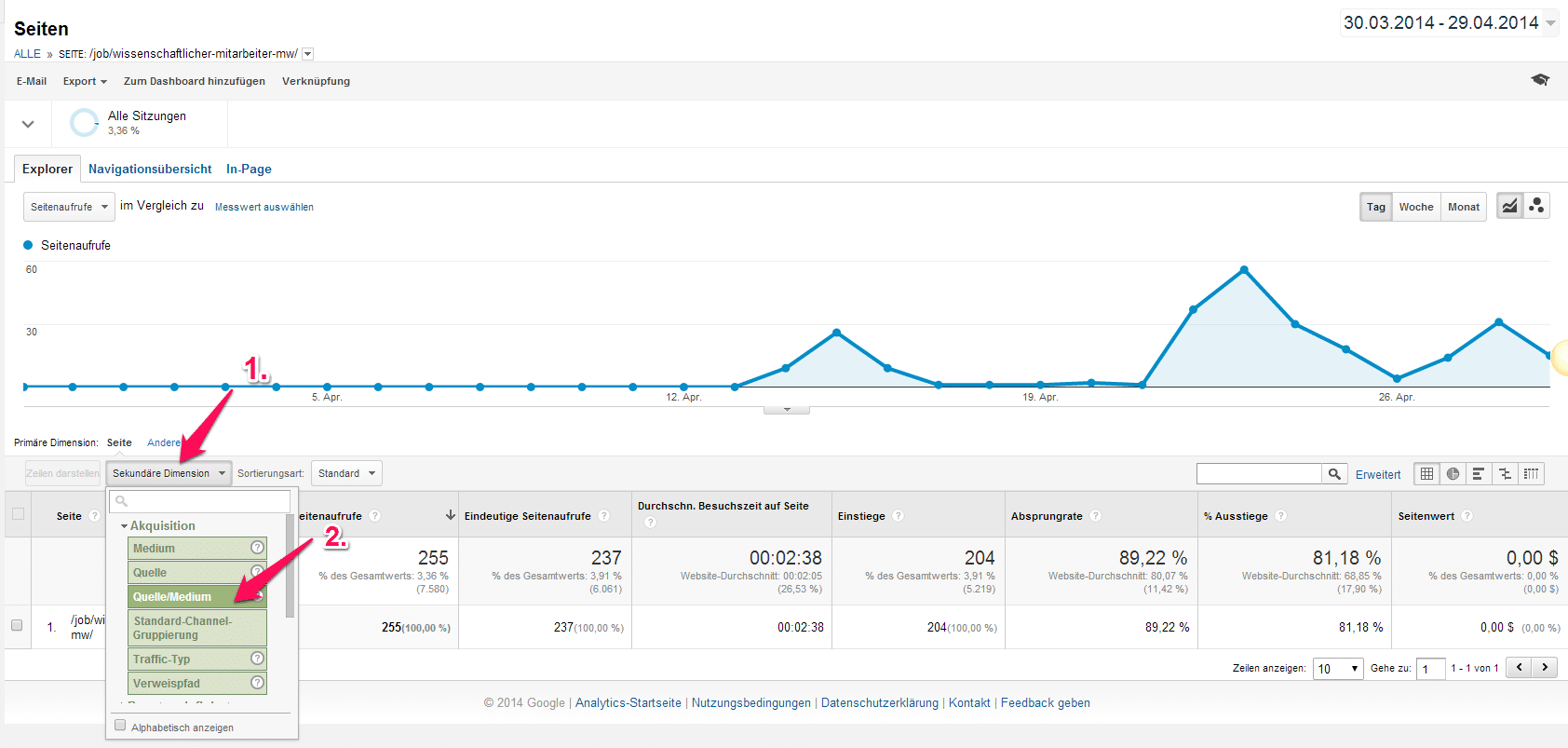
In der gleichen Ansicht wählen wir aus: Sekundäre Dimension -> Quelle/Medium und erhalten die Zusammensetzung der Besucherquellen für die ausgewählte Anzeige.
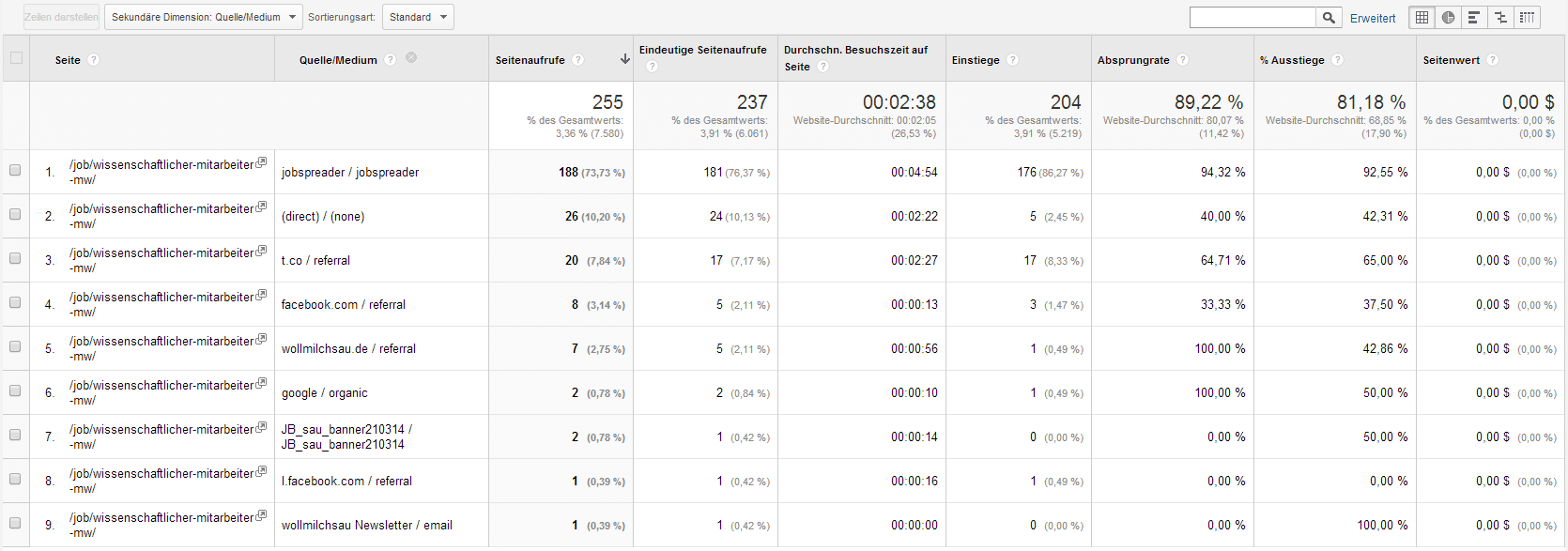
Im Fall unserer Beispiel-Anzeige kamen also die meisten Besucher also über die Promotion mit unserem Tool Jobspreader, Direktbesuche der Jobbörse und zusätzliche Veröffentlichung auf einem Twitteraccount (t.co = Twitter). Jetzt wollen wir nur noch wissen, wie die Zusammensetzung der Quellen für die gesamte Seite aussieht. Dazu klicken wir auf: Bericht -> Akquisition -> Übersicht -> Primäre Dimension (->Top-Quellen).

Und so sieht das Ergebnis für unsere Test-Seite aus. Die meisten Besucher sind direkte Besucher, sprich sie geben den Link zur Jobbörse z.B. direkt in der Browser-Leiste ein, oder klick auf einen Link in einer PDF-Datei oder in einer Mail. Das überrascht mich nicht. Wir führen gerade mehrere Aktionen zur Promotion der HR-Jobbörse durch. Sie scheinen, Ergebnisse zu bringen. Weitere starke Quellen sind Jobspreader (4fb.in gehört auch dazu) und unsere Seite wollmilchsau.de
MEHR REICHWEITE & FLEXIBILITÄT FÜR DEINE STELLENANZEIGEN
JETZT DEMO ANFORDERN!
Mit sehr wenig Aufwand haben wir somit ein erstes gutes Bild von den Vorgängen auf unserer Seite erhalten, mit dem man bereits gut argumentieren kann. Ich hoffe, einige von Euch finden dieses kleine Tutorial hilfreich. Ich würde mich über Euer Feedback freuen, ob die Erklärung nützlich und einfach genug ist und was für weitere Fragen und Probleme im Bereich Analytics bestehen.



